Reference
Unity基础:DrawCall从入门到精通 - 知乎 (zhihu.com)文章很长
https://www.cnblogs.com/zerobeyond/p/17739766.html
游戏图形批量渲染及优化:Unity静态合批技术 - GameRes游资网
【Unity游戏开发】合批优化汇总 - 知乎 (zhihu.com)讲的比较好
什么是DrawCall
我们先来翻译翻译,绘制调用,没错就是CUP向GPU调图形渲染的命令。
DrawCall本身的含义其实很简单,就是CPU调用图像应用编程接口(API),如OpenGL中的glDrawElecments命令或者是DirectX中的DrawIndexedPrimitive命令,来命令GPU进行渲染的操作。
Batches通常被我们称为绘图调用(Draw Call)。这些是简单的绘制命令,例如,在此处绘制此对象,然后在此处绘制另一个对象。这主要是关于使用当前全局渲染状态绘制相同着色器、相似参数的对象。
提交DrawCall的步骤:
准备数据(Prepare Data):在CPU上准备渲染所需的数据,例如顶点坐标、法线、纹理坐标等。
设置渲染状态(Set Render State):设置渲染状态,包括渲染目标、深度测试、混合模式、着色器程序等。
绘制调用(Draw Call):通过API调用(如OpenGL或DirectX)发起绘制命令,告诉GPU如何绘制准备好的数据。
命令缓存区
CPU的DrawCall,并不会直接给到GPU,可能是因为两者运行速度不一致,在两者之间有一个命令缓冲全区。
其实现在我已经看到过很多由于速度不一致而设计的缓冲区,例如:寄存器、消息队列
所以我才大胆猜测,还有内存实际上也是效率问题引起的,如果CPU只有等待GPU处理完一个命令才给下一个命令效率太低下了。
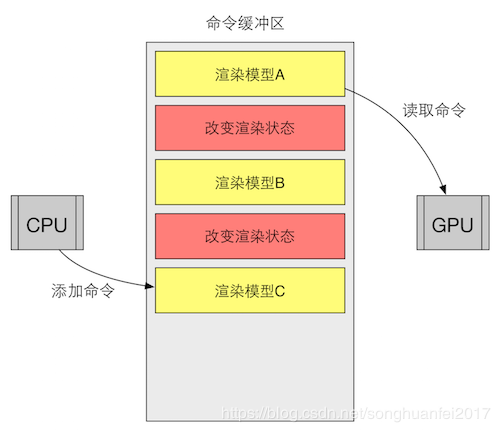
SetPasses
上图中黄色的方框”渲染模型A”就是DrawCell,红色的方框是SetPasses。
但是,SetPasses描述了一种更昂贵的操作:材质更改。更改材质很昂贵,因为我们必须设置一个新的渲染状态。其中包括着色器参数和管线设置,例如Alpha Blending,Z-Test,Z-Writing。
所以材质的更改也是一个性能上的大问题。我们要尽量使用相同的材质避免SetPasses产生更大的消耗。在共享材质的情况下我们的SetPasses只用提交一次。
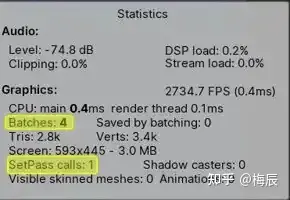
最后,你可以并且应该使用Unity Frame Debugger。该工具将为你显示当前视图正在发出的特Draw Call(Batches)。你可以点击_Window → Analysis → Frame Debugger_菜单打开它。
批处理
提交大量很小的DrawCall会造成CPU的性能瓶颈,即CPU把时间都花费在准备DrawCall的工作上了。那么很显然的一个优化方法就是把很多小的DrawCall合并成一个大的DrawCall,这就是批处理。
游戏开发人员使用批处理将相似对象的渲染分组到同一个Draw Call中。这样,CPU只需支付一次DrawCall即可渲染多个对象。
在批处理中,相似定义为在不同的对象上使用相同的材质。如果完成此步骤,则可以完成最复杂的步骤。
技术1:静态批处理
一下皆引用自:Unity基础:DrawCall从入门到精通 - 知乎 (zhihu.com)
适用于不会在运行时改变的网格,Unity编辑器在构建阶段将多个静态网格合并成一个网格,并生成一个合并后的网格文件。这样可以显著减少Draw Call的数量,但缺点是无法在运行时动态修改这些网格。这样将静态物体的网格进行合并,就只需要一次DrawCall。
在Player Setting,如图所示。选择您要启用的目标平台,打开Static Batching。
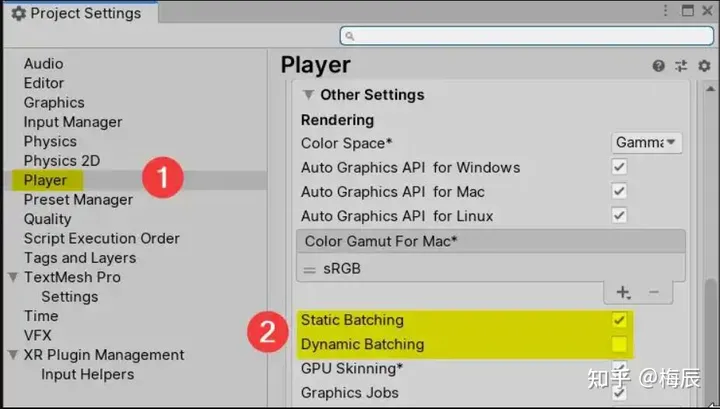
更准确地说,Unity将查找启用了batching static标志的对象。然后,Unity将尝试合并公用材质的对象。
Unity静态批处理通过创建包含各个网格的巨大网格来工作。但是Unity也会保持原始网格的完整,因此我们仍然能够单独渲染它们。
这样我们可以仅绘制可见视野内的对象,而丢弃不可见的对象,使得视锥裁切正常工作。
通过将所有网格都放在一个网格中,我们就可以在不更改渲染状态的情况下全部绘制它们。
静态批处理的主要限制是每批可以具有的顶点和索引的数量,通常为每个64k,可以在此处检查限制更新(如果有)。
静态批处理的缺点是增加了内存使用量。如果您有100个石头,每个石头模型占用1MB,则可以预期内存使用量将超过100MB。发生这种情况的原因是,巨大的批处理网格将所有石头一起包含在一个网格中。
但是,内存使用对你来说不是问题。毕竟,你可以查看我的Unity可寻址对象教程,该教程将帮助你节省大量内存。
技术2:Unity GPU Instancing
GUP Instancing 可以用于绘制非静态的对象,因为它通过传递一个transform给GPU而得到绘制,相同的物体仍然只有一次DrawCall。
这是针对每种材质激活GPU Instancing设置,如下所示。
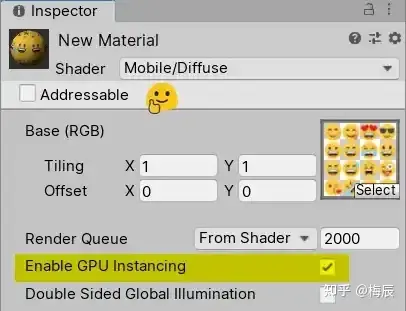
Unity GPU Instancing:材质设置
GPU实例化让你可以非常高效地绘制相同的网格几次。Unity通过向GPU传递转一个Transform列表来做到这一点。毕竟,每块石头都有自己的位置,旋转和缩放。
与静态批处理相比,这是一项强大的技术,因为它不会激增内存使用量,并且不需要对象是静态的。
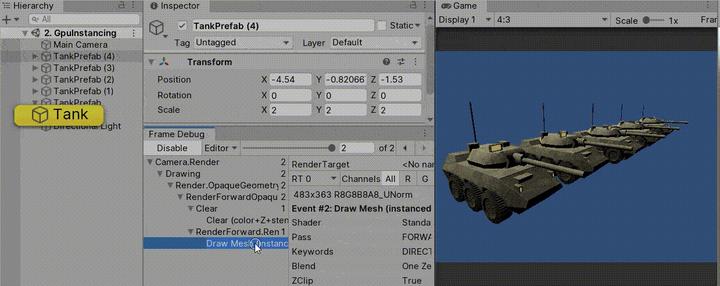
要使用GPU Instancing,你只需要在材质检视面板中启用它即可。如果你有多个具有相同网格和材质的对象,那么Unity对它们将自动进行批处理。
但是,创建Transform列表会降低性能。如果在游戏过程中没有物体移动/旋转/缩放,则只需支付一次此开销。但是,如果对象每帧都更改一次,则需要每帧支付一次开销。
推荐一个插件:GPUInstance比Unity默认的要好用的多。
技术3:动态批处理
适用于需要在运行时动态修改的网格,Unity会在运行时动态合并具有相同材质的网格,以减少Draw Call的数量。动态批处理不需要预先合并网格,而是在运行时根据需要动态合并网格,因此适用于需要动态创建、销毁或修改的网格。
但是,请记住,Unity动态批处理受到更加严格的限制。你只能将其应用于具有少于300个顶点和900个顶点属性(_颜色,UV_等)的网格。材质也应使用single-pass着色器。此处有完整的限制列表。
出现此限制的原因是在运行时创建这些批处理的CPU性能成本。与单独发出绘图调用相比,超过300个顶点很难证明批量CPU的成本合理。
不仅如此,动态批处理非常不可预测。你无法真正确定对象将如何被批处理。结果通常会随着帧的变化而变化。打开Unity Frame Debugger并查看结果,在每帧之间动态批处理的结果发生巨大变化是令人困惑的。
我认为,这应该是你的不得已的方法。但是,嘿,它仍然是一种有用的工具,请不要忽略它。
技术4:Unity运行时批处理API
Unity使你可以访问2个强大的API,以在运行时合并网格。
假设你正在开车。在车的内部,你会看到一些元素,例如座椅,把手,挡风玻璃和你收藏的咖啡杯。你可以在比赛开始之前设定这些元素。
一旦你做出选择并开始比赛,这些元素就会在你的赛车中变成静态的(无法再次更改)。让我解释一:
车内部的物品、零件都变成相对静态的了。
但是,Unity认为所有这些都是动态的。这就是为什么在这种情况下无法进行静态批处理的原因。
尽管如此,我们仍然可以通过使用静态批处理API,手动创建合批。
最简单的方法是使用StaticBatchingUtility.Combine。该函数传入一个根游戏对象,并将遍历其所有子对象并将其几何形状合并为一个大块。一个容易遗漏的限制是,要批处理的所有子网格的导入设置必须允许开启_CPU read/write_。
第二种方法是使用Mesh.CombineMeshes。此函数间接获取网格列表并创建组合的网格。然后,你可以将该网格分配给mesh filter渲染。
我简化了这两种功能的解释。查看文档以获取有关如何使用它们的详细信息。
在下图中,您将看到我如何应用StaticBatchingUtility API的功能在运行时将一些动态坦克批合并为一个网格。
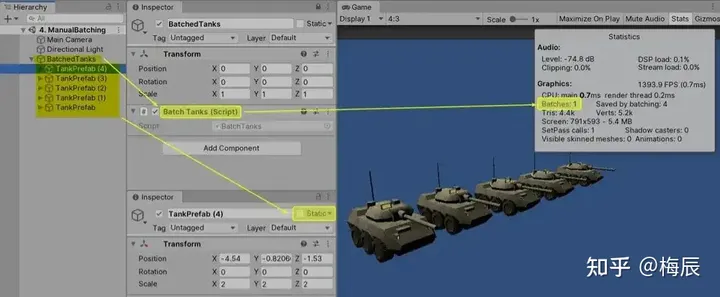
静态合批与动态合批对比
静态合批
优点:
- 性能高效: 静态合批将多个渲染对象的顶点数据合并成一个大的顶点缓冲区,减少了状态切换和数据传输的开销,从而提高了渲染性能。
- 减少 DrawCall 调用: 合并多个渲染对象可以减少 API 调用次数,降低 CPU 开销,提高渲染效率。
- 减少资源消耗: 合并顶点数据后,可以减少顶点缓冲区的数量和内存占用,节约资源。
缺点:
- 限制性强: 静态合批适用于不经常变化的渲染对象,一旦合并后的顶点数据发生变化,就需要重新生成合并后的顶点缓冲区,会增加额外的开销。
- 内存占用: 如果需要合并大量渲染对象,可能会占用较多的内存,特别是对于大型场景而言。
动态合批
优点:
- 灵活性强: 动态合批可以处理频繁变化的渲染对象,能够实时更新顶点数据而不需要重新生成合并后的顶点缓冲区。
- 节省内存: 由于动态合批不需要在内存中保存合并后的顶点数据,因此节省了内存空间。
- 适应性强: 适用于需要动态添加、删除、修改渲染对象的场景,例如粒子系统、动态网格等。
缺点:
- 性能开销: 动态合批需要在每一帧重新计算合并后的顶点数据,可能会增加 CPU 开销,特别是当渲染对象数量较多时。
- DrawCall 调用频繁: 每次更新渲染对象都需要进行一次合批操作,可能会增加 API 调用次数,降低渲染效率。
- 实现复杂: 实现动态合批需要考虑更多的细节,例如合并策略、更新频率等,相对而言比较复杂。
综上所述,静态合批适用于渲染对象不经常变化且数量较多的场景,而动态合批适用于需要频繁更新渲染对象且数量较少的场景。选择合适的合批方式需要根据具体的需求和场景来决定。